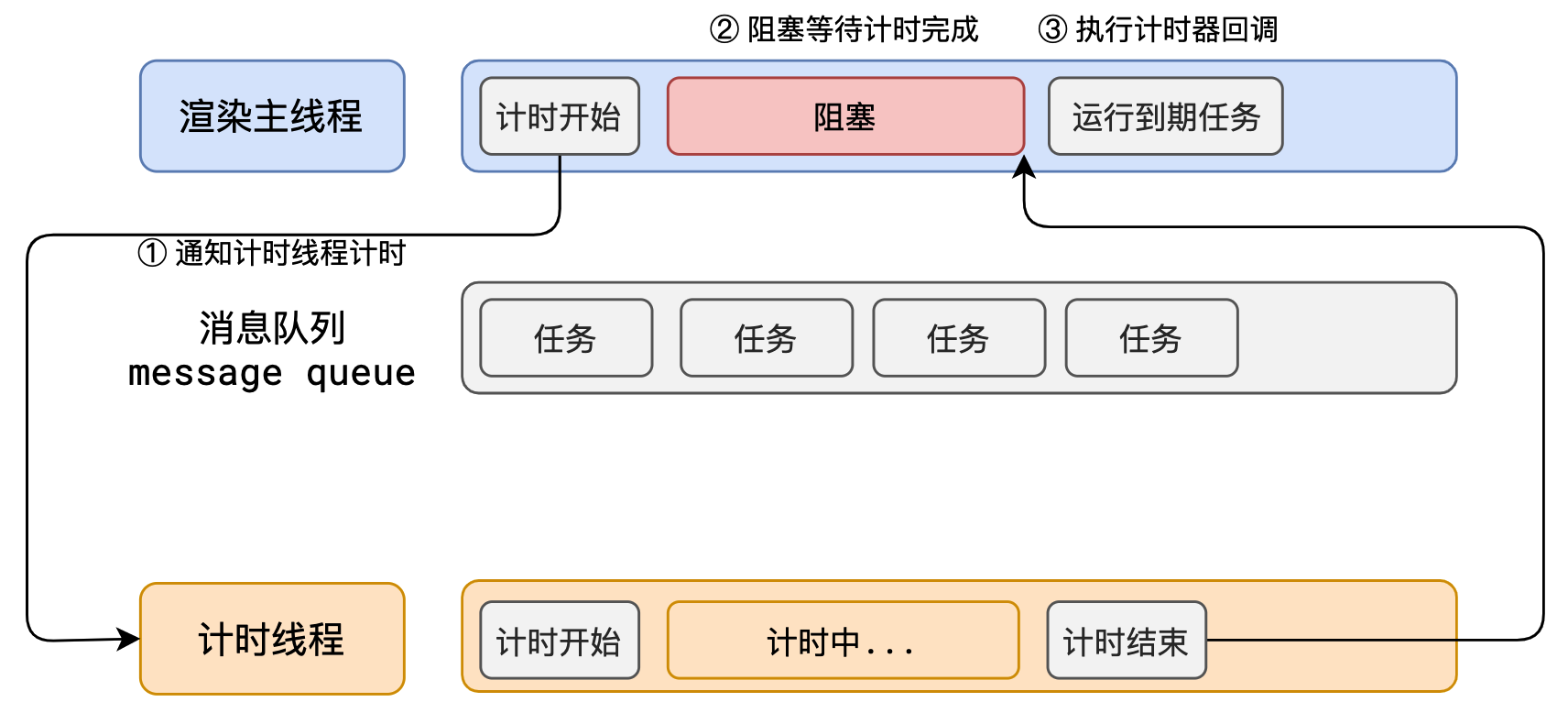
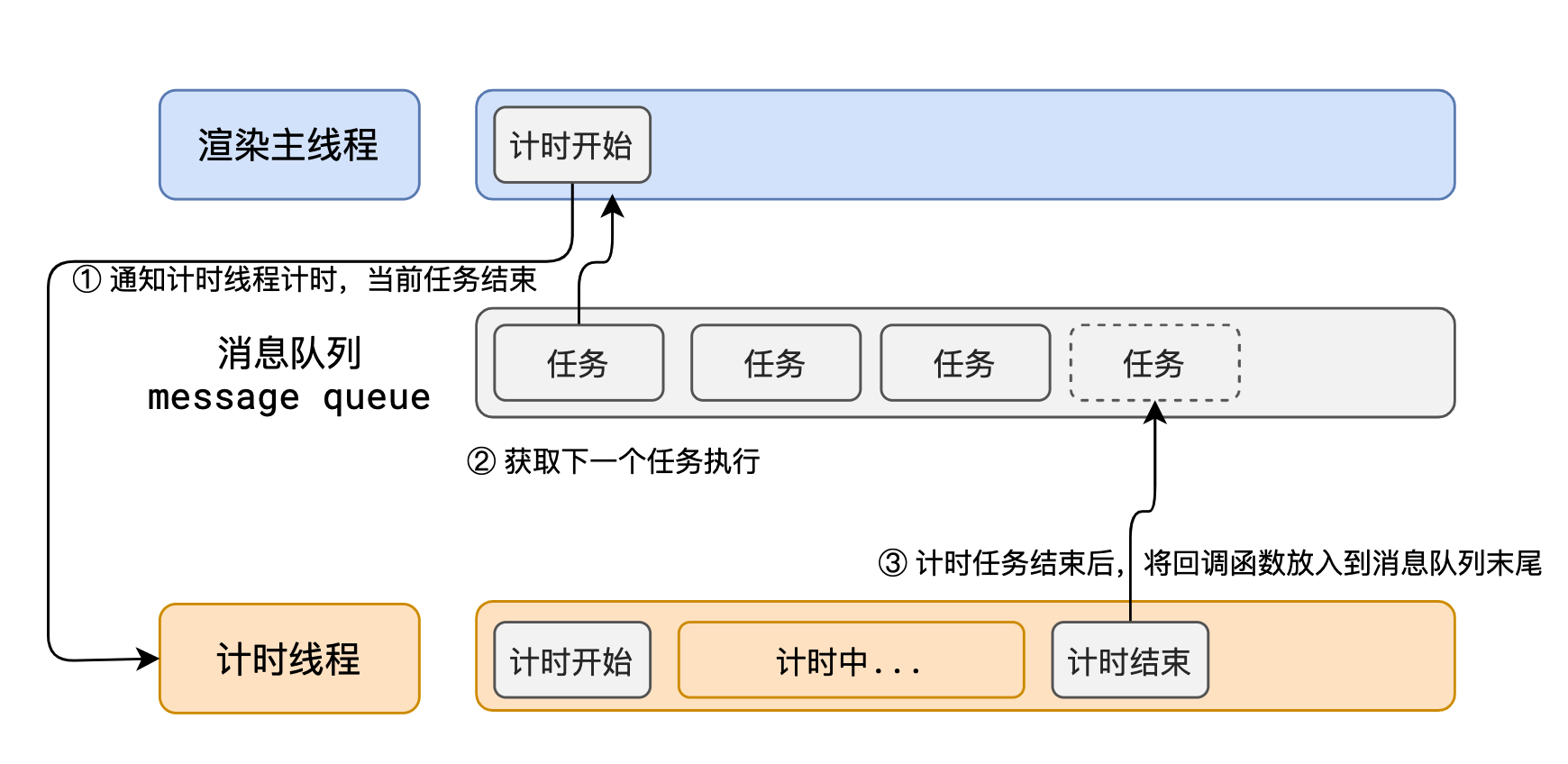
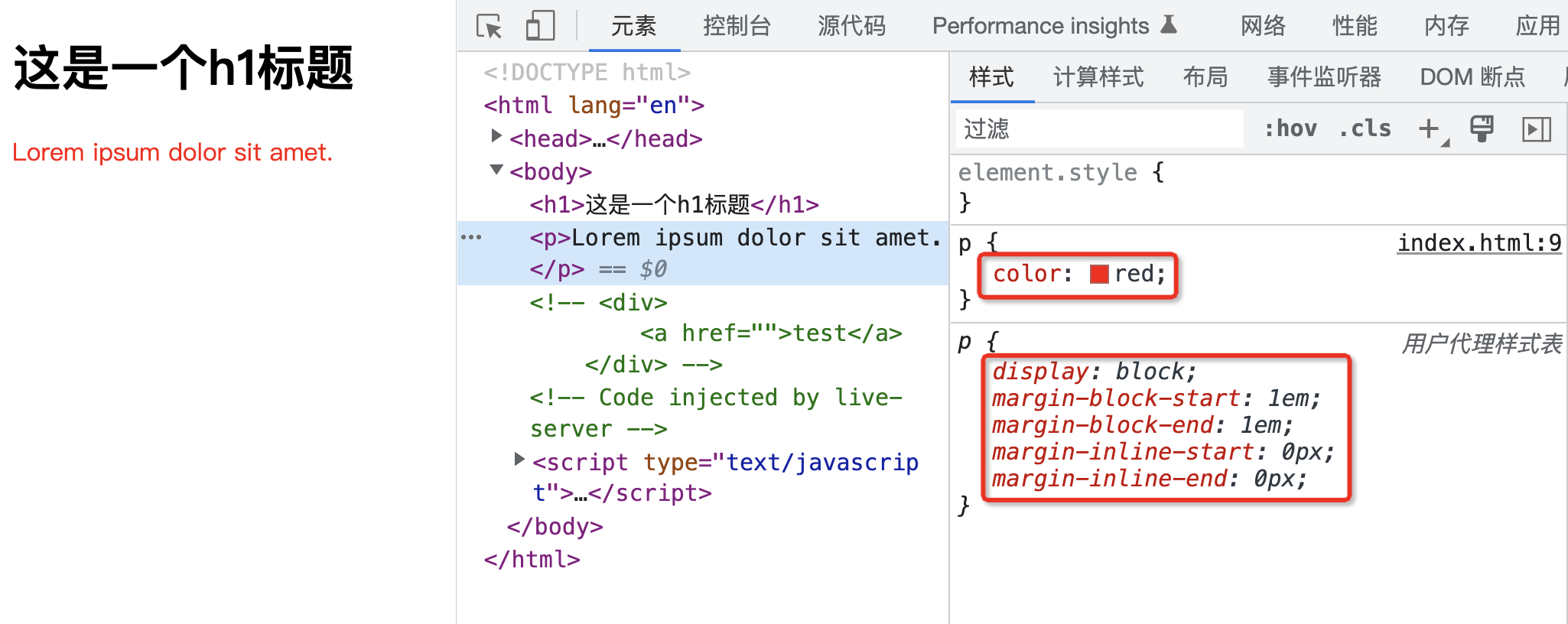
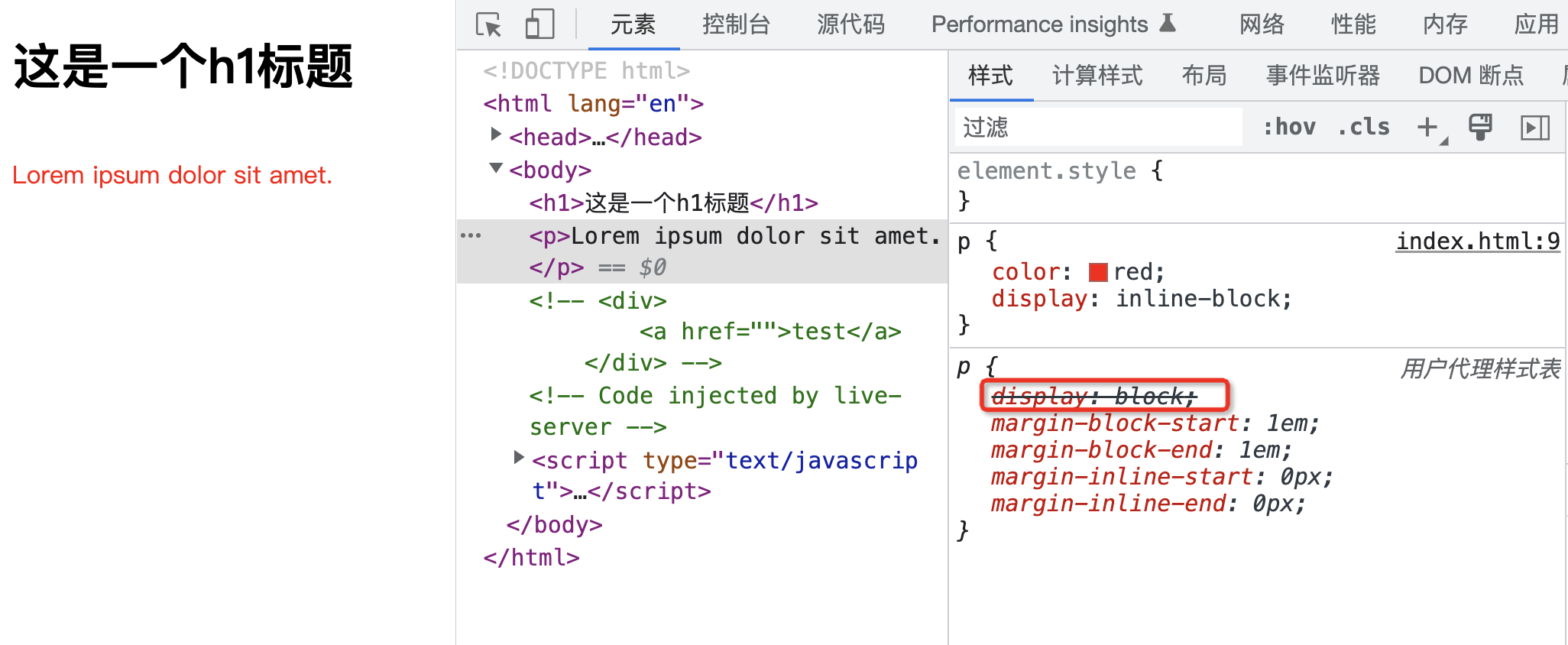
群辉通过scma.sh获取ssl证书
使用 acme.sh 为 Synology NAS 配置 HTTPS 证书
准备
- 公网IP,动态的也可以
- 域名,有权限添加dns解析
安装 acme.sh
1 | sudo su |
配置 DNS
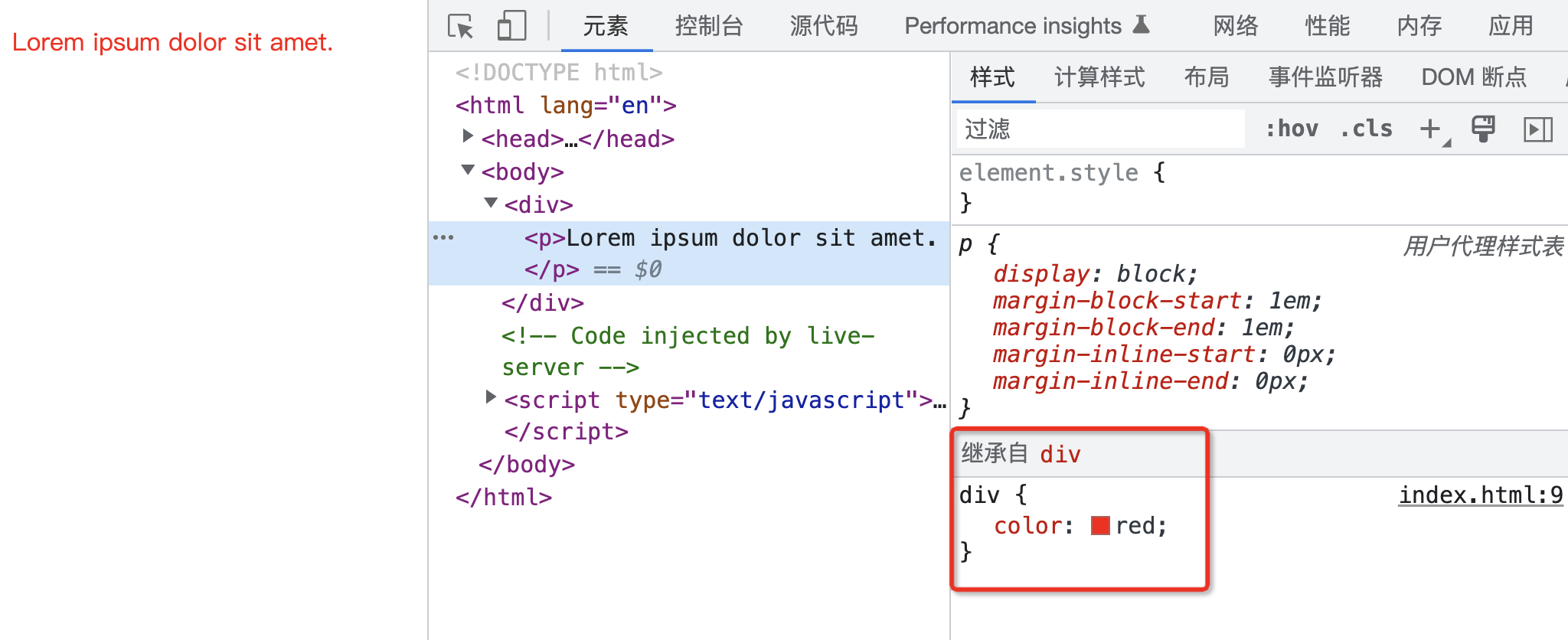
对于 Aliyun,我们将设置两个环境变量,acme.sh(特别是 dnsapi 子目录中的 dns_ali 脚本)将读取这些变量来设置 DNS 记录。您可以在这里获取您的 aliyum API 密钥。
1 | export Ali_Key="<key>" |
别忘了添加【管理云解析(DNS)的权限】
如果您使用其他 DNS 服务,请检查 dnsapi 目录和 DNS API 指南。许多 DNS 提供商的说明已包含在内。您还可以找到如何添加其他 DNS 服务的说明,但这需要一
创建证书
现在是时候为您的域名创建证书了:
1 | # 这些命令假设您仍在同一个终端中,并已运行上面描述的必要命令。 |
部署默认证书
我们将使用 Synology DSM 的 deployhook 来部署我们的证书。这将覆盖默认证书(如果您尚未为其设置任何描述),您可以在本节稍后了解如何创建用于其他服务的新证书。
以下代码块中的命令假设您仍在同一个终端中,并执行了必要的命令。
使用临时或现有管理员用户部署
(推荐)使用自动创建的临时管理员用户部署
如果您在 DSM 中安装了 acme.sh,建议您尝试自动临时用户身份验证方法进行部署(DSM 应该已经具备所需的内置工具,如果没有,我们会告诉您):
1 | export SYNO_USE_TEMP_ADMIN=1 |
通过这种方式,您无需提供任何管理员凭据,部署脚本本身将利用 Synology 内置工具完成身份验证,因此它设计仅支持本地部署,不能用于 Docker 部署或远程部署。
脚本将加载之前保存的配置以供后续部署,因此如果您想回到使用现有管理员用户进行部署,您需要首先执行 export CLEAR_SYNO_USE_TEMP_ADMIN=1。部署脚本退出后,临时管理员用户应该未被创建或已经被删除,但如果脚本意外退出(例如,通过按“Ctrl+C”中止),它可能仍然保留,在这种情况下,您可以安全地通过“控制面板”删除它。
使用现有管理员用户部署
如果您更喜欢使用现有的管理员用户进行部署,或者上述方法不可用(例如,安装在 Docker 中,想要远程部署等),您需要提供自己的凭据:
1 | # 单引号防止某些特殊字符的转义问题 |
请注意,如果由 SYNO_USERNAME 指定的用户启用了双因素身份验证(2FA),脚本将要求您手动输入 TOTP 代码,就像在网页界面登录一样(如果您没有通过 export SYNO_OTP_CODE=XXXXXX 提供代码)。它还将要求您输入设备名称进行验证(也可以通过 export SYNO_DEVICE_NAME=CertRenewal 提供),然后获取必要的信息,以便在未来的操作中省略 TOTP,因此您无需再次手动输入。
顺便提一下,如果您以前使用此脚本进行部署,所需的信息现在被称为参数“设备 ID”,如果您是专业用户并希望手动获取它,您仍然可以,方法简要说明:通过其网站登录到 DSM,确保在要求输入 OTP 时选择“记住此设备”,获取 did cookie 的值并设置环境变量 SYNO_DEVICE_ID:
1 | export SYNO_DEVICE_ID='YOUR VALUE' |
使用 HTTPS 部署
当我们希望使用 HTTPS 部署新证书并连接到“localhost”时,需要在部署命令中添加 --insecure 选项以防止 curl 错误。请参阅 [https://github.com/acmesh-official/acme.sh/wiki/Options-and-Params]。如果您启用了 HTTP/2,您仍然可能会收到 curl 16 错误,这可能是由于 NAS 上缺少 http2 依赖项,但脚本仍会成功。
1 | # export SYNO_HOSTNAME="localhost" # 如果不使用 localhost,则指定 |
此外,如果您使用临时管理员方法进行部署,为了避免混淆,SYNO_HOSTNAME 的值必须指向当前本地计算机(可以是 localhost 或 127.0.0.1),但是如果您的自定义 SYNO_HOSTNAME 确实指向当前本地计算机,则应在部署前执行 export SYNO_LOCAL_HOSTNAME=1。
部署额外证书
通过指定不同的 SYNO_CERTIFICATE(并设置 SYNO_CREATE=1 用于创建),我们可以向 DSM 部署多个证书。
1 | # SYNO_CERTIFICATE 是在 DSM 控制面板的“安全性 -> 证书”下显示的描述 |
配置证书续订
要在未来自动续订证书,您需要在任务调度器中配置一个任务。不建议将其设置为自定义 cronjob(如之前在本维基页面中描述的那样),因为 DSM 安全顾问会告诉您有关未知 cronjob 的严重警告。
在 DSM 控制面板中,打开“任务调度器”,并为用户定义的脚本创建一个新计划任务。
- 常规设置:任务 - 更新默认证书。用户 - root
- 计划:设置每周续订。例如,每周六上午 11:00。
- 任务设置:用户定义的脚本:
1 | # 续订证书 |
修复 Synology DSM 升级后的环境问题
1 | ./acme.sh --force --upgrade --nocron --home . |
或者手动将以下行添加到 /root/.profile 中:
1 | . "/usr/local/share/acme.sh/acme.sh.env" |